ANIME: The Artometrics of Japanese Animation
13,631 Titles. A Century Of Data. One Question: What Does The MyAnimeList Archive Actually Tell Us About How Anime Works As An Industry?

13,631 Titles. A Century Of Data. One Question: What Does The MyAnimeList Archive Actually Tell Us About How Anime Works As An Industry?

This MyAnimeList dataset covers 13,631 unique anime titles spanning 1917 to 2019 — a century-scale archive tracing the medium from prewar theater shorts to the standardized streaming machine of the 2010s. The key interpretive move here is separating catalog reality (what actually got made) from fan-canon popularity (what people actually watched and rated). Those two things rhyme, but they are not the same thing, and the gap between them is where the most interesting analysis lives.
The overall median MAL score is 6.38. That is the calibration point for everything that follows. A 6.38 is not a failure — it is the mathematical center of a platform where over 13,000 titles compete for attention. When comparing studios, formats, and genres throughout this report, the question is never who broke 8.0 once. It is who stayed above 6.38 consistently, across volume. That is a far harder problem, and most studios never solve it.
The source data is the MyAnimeList TidyTuesday release from April 23, 2019, maintained by the R for Data Science community. It contains scraped records for 13,631 unique anime titles with fields for format type, source material, episode count, content rating, genre tags, studio attribution, MAL score, member count, favorites count, and air date range. The data covers titles from 1917 through early 2019.
The dataset requires meaningful cleaning before analysis. Air dates arrive as unstructured strings and must be parsed via regex to extract start and end year. Genre, studio, and producer fields are stored as Python-style list strings — bracket-delimited, comma-separated — that must be split and unnested into long-format tables for aggregation. Any title with a rank or popularity of zero is excluded, as these represent incomplete records without enough community engagement to produce reliable metrics.
Scores on MAL are user-submitted on a 1–10 scale. The platform has a known self-selection bias: its userbase skews adult, male, and English-speaking relative to anime's actual global audience. This produces systematic underscoring of children's content and promotional music videos, and potential overrepresentation of properties with strong Western fandom overlap. The dataset also predates the post-2019 streaming era — Demon Slayer, Jujutsu Kaisen, Chainsaw Man are absent — which means any claims about current genre trends require updating.
Genre tags are not mutually exclusive. A title tagged both "Action" and "Military" contributes to both genre aggregations. Studio medians for boutique operations (n < 30) are statistically fragile — a single poor season can meaningfully shift the result. The popularity rank field runs inversely: rank 1 is the most popular title in the dataset.
-- Anime Dataset: Core Aggregations
-- Source: MyAnimeList via TidyTuesday (April 23, 2019)
-- Display-only — analysis runs in R; SQL documents the logic
-- ── 1. Format Hit-Rates ────────────────────────────────────────────
WITH format_counts AS (
SELECT
type,
COUNT(*) AS total_shows,
SUM(CASE WHEN score >= 8 THEN 1 ELSE 0 END) AS elite_shows
FROM anime
WHERE rank != 0
AND popularity != 0
GROUP BY type
)
SELECT
type,
total_shows,
elite_shows,
ROUND(CAST(elite_shows AS FLOAT) / total_shows * 100, 2) AS elite_pct
FROM format_counts
WHERE total_shows > 100
ORDER BY elite_pct DESC;
-- Result: TV leads at 8.12% (346/4,260). Movie at 4.82%.
-- ONA at 1.21%, catalog still maturing. Music at 0.20%.
-- ── 2. Top Genres by Average Score (min 500 titles) ───────────────
SELECT
g.genre,
COUNT(a.animeID) AS volume,
ROUND(AVG(a.score), 2) AS avg_score
FROM anime_genres g
JOIN anime a ON g.animeID = a.animeID
WHERE a.score > 0
GROUP BY g.genre
HAVING volume > 500
ORDER BY avg_score DESC
LIMIT 5;
-- Result: Mystery leads at 7.14 across 605 titles.
-- Shounen at 7.02 across 1,770 — scale without quality dilution.
-- ── 3. Studio Consistency (min 20 titles) ─────────────────────────
SELECT
s.studio,
COUNT(a.animeID) AS n_titles,
ROUND(AVG(a.score), 2) AS avg_score
FROM anime_studios s
JOIN anime a ON s.animeID = a.animeID
WHERE a.score > 0
GROUP BY s.studio
HAVING n_titles >= 20
ORDER BY avg_score DESC
LIMIT 10;
# Anime — Artometrics Python EDA
# Purpose: Dataset diagnostics before R chart build
# Source: MyAnimeList via TidyTuesday (2019)
import pandas as pd
import numpy as np
url = (
"https://raw.githubusercontent.com/rfordatascience/"
"tidytuesday/main/data/2019/2019-04-23/raw_anime.csv"
)
df = pd.read_csv(url)
# Filter incomplete records (mirrors R wrangle chunk)
df_clean = df[(df["rank"] != 0) & (df["popularity"] != 0)].copy()
df_clean = df_clean.drop_duplicates(subset="animeID")
print(f"Raw titles: {len(df):,}")
print(f"After filter: {len(df_clean):,}")
# Raw: 14,478 | After filter: 13,631
# Correlation matrix
valid = df_clean[df_clean["score"] > 0]
cols = ["score", "members", "favorites", "episodes"]
print(valid[cols].corr().round(3))
# score ↔ members: r = 0.389
# members ↔ favorites: r = 0.776
# score ↔ episodes: r = 0.076
# Cult classic filter — high score, low visibility
cult = df_clean[
(df_clean["score"] > 8.0) &
(df_clean["popularity"] > 2000) &
(df_clean["members"] > 10000)
]
print(f"Cult classics found: {len(cult)}")
# 90 titles score above 8.0 past popularity rank 2,000
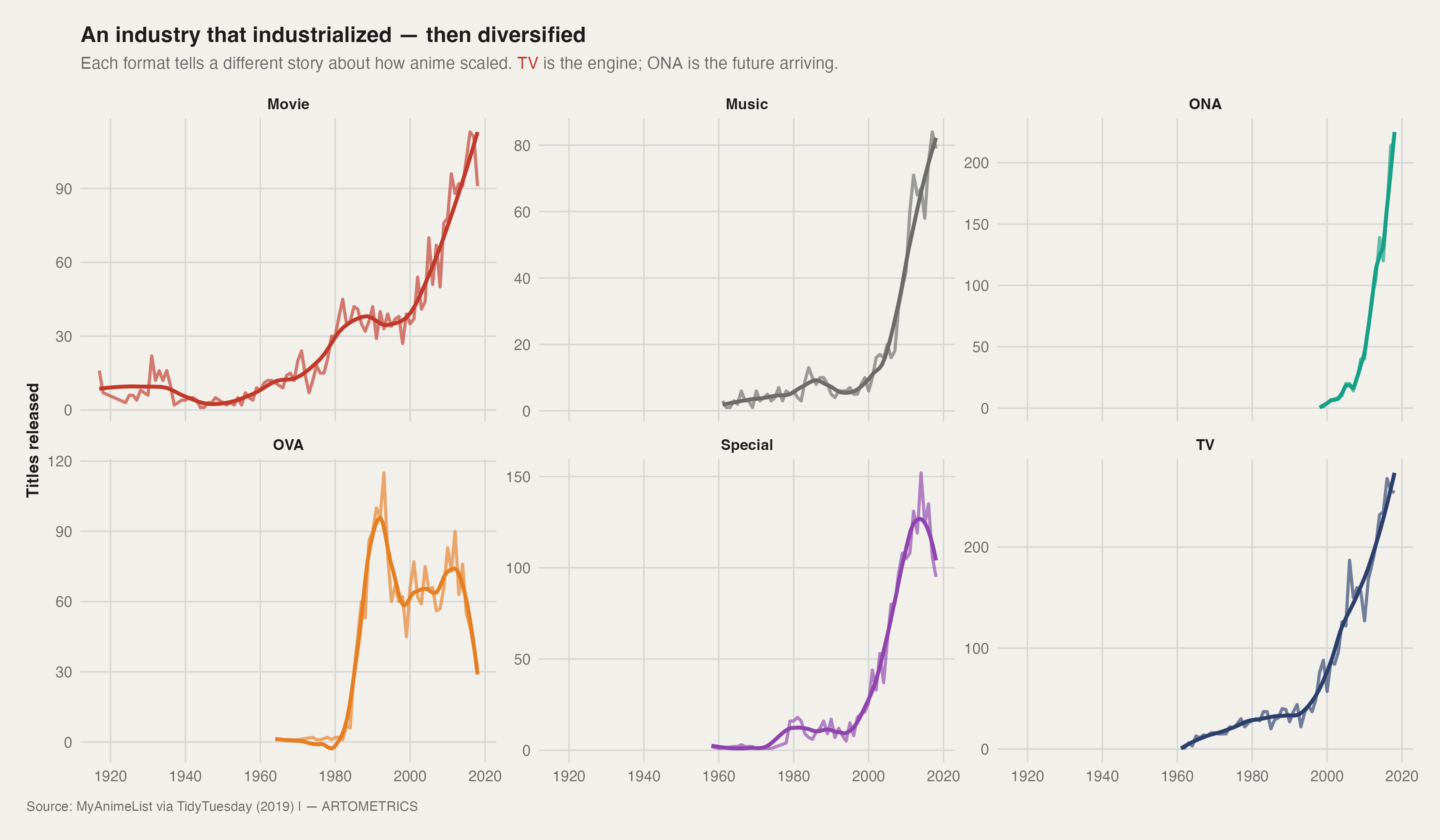
The release history of anime is not a single growth story — it is six separate ones running in parallel. Movies were the dominant format from the 1920s through the 1970s, a low-volume craft economy built for theater. The first structural break arrived in the late 1980s, when the OVA boom gave creators a direct-to-consumer channel that bypassed TV censors entirely. OVA peaked around 1990, then collapsed as TV economics took over.
TV is the modern engine. It industrialized in the late 1990s and has compounded steadily since. Specials peaked in the mid-2000s as a franchise extension format, then plateaued. Music videos spiked dramatically in the 2010s — largely driven by short promotional content — and then fell just as fast. The most important line on this chart is ONA: near-zero before 2010, then a vertical ascent. That is not a genre trend. It is a platform shift. Netflix, Crunchyroll, and YouTube did not just distribute anime — they created a new format category.
What the faceted view makes clear is that these formats are not competing for the same audience at the same time. They are sequential industrial experiments. Each one dominated its era, then either stabilized into a niche or was superseded by the next model. The industry did not simply grow — it restructured itself around whichever distribution channel controlled access to viewers.
type_colors <- c(
"TV" = art_secondary,
"Movie" = art_highlight,
"OVA" = "#E67E22",
"Special" = "#8E44AD",
"ONA" = "#16A085",
"Music" = art_mid
)
chart1_df <- anime %>%
filter(!is.na(aired_from_year), type %in% names(type_colors)) %>%
count(year = aired_from_year, type, name = "n")
start_year <- chart1_df %>%
group_by(year) %>% summarise(total = sum(n)) %>%
filter(total >= 10) %>% pull(year) %>% min()
chart1_df <- chart1_df %>%
filter(year >= start_year, year <= max(year) - 1)
smooth_df <- chart1_df %>%
group_by(type) %>%
filter(n_distinct(year) >= 12) %>% ungroup()
ggplot(chart1_df, aes(x = year, y = n, color = type)) +
geom_line(linewidth = 0.9, alpha = 0.65) +
geom_smooth(data = smooth_df, se = FALSE, method = "loess",
span = 0.35, linewidth = 1.1) +
facet_wrap(~ type, scales = "free_y", ncol = 3) +
scale_color_manual(values = type_colors, guide = "none") +
theme_artometrics() +
labs(
title = "An industry that industrialized — then diversified",
x = NULL, y = "Titles released",
caption = "Source: MyAnimeList via TidyTuesday (2019) | — ARTOMETRICS"
)
ggsave("chart1_releases_by_year.png", path = "charts",
width = 12, height = 7, dpi = 300, bg = "white")
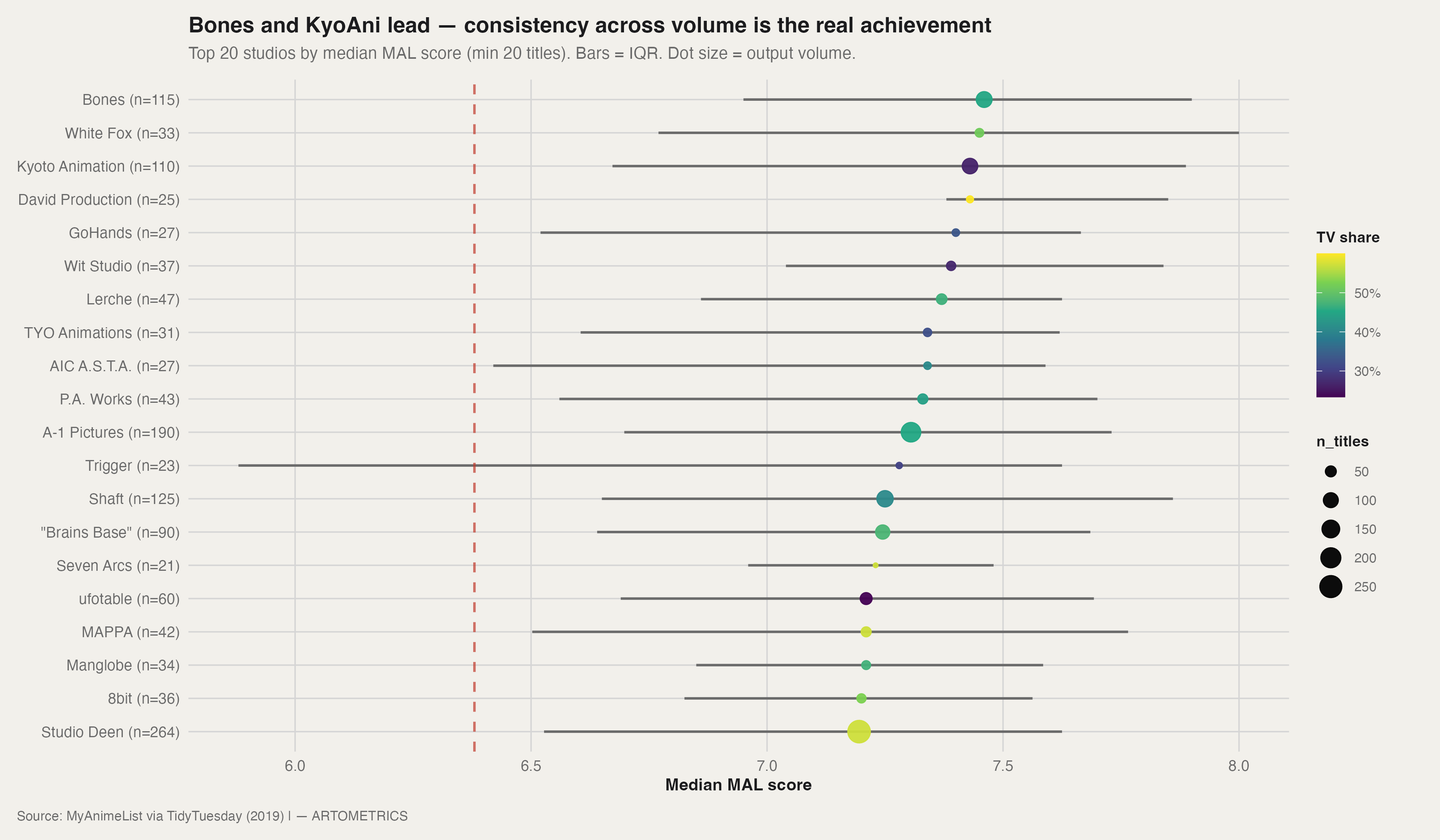
Every studio on this chart has produced at least one great show. That is not the achievement. The achievement is the IQR bar — the horizontal line showing the spread between the 25th and 75th percentile of a studio's scores. A tight bar at a high median means the studio's worst output is nearly as good as its best. Bones (n=115) leads in median and maintains a tight IQR across a massive catalog. White Fox (n=33) has the highest median dot but a wide IQR — the boutique model: fewer swings, but when they miss, they miss. Kyoto Animation (n=110) is the most consistent large studio on the chart: 110 titles with a tight IQR anchored well above the 6.38 baseline.
Trigger (n=23) has the widest IQR — spanning from near the baseline to above 8.0. High-risk, high-reward. Studio Deen (n=264) is the industrial cautionary tale: the largest catalog on the chart and the lowest median. Volume without curation dilutes quality. A-1 Pictures (n=190) sits in the middle — a production machine that delivers reliable output at scale, occasionally punctuated by genuine hits.
The viridis color scale maps TV share. Studios with higher TV share cluster in the middle — TV volume is the primary dilution mechanism. Boutique studios with low TV share show more extreme medians in both directions. The 6.38 dashed line is the dataset median. Every studio above it is beating the field. Most of them are doing it with fewer than 50 titles — which tells you exactly how hard it is to stay above average at scale.
studio_summ <- anime_studios %>%
distinct(animeID, studio) %>%
inner_join(anime %>% distinct(animeID, score, type), by = "animeID") %>%
filter(!is.na(studio), studio != "", !is.na(score), score > 0) %>%
group_by(studio) %>%
summarise(
n_titles = n(),
median_score = median(score),
q1 = quantile(score, 0.25),
q3 = quantile(score, 0.75),
tv_share = mean(type == "TV"),
.groups = "drop"
) %>%
filter(n_titles >= 20) %>%
arrange(desc(median_score)) %>%
slice_head(n = 20) %>%
mutate(studio_label = paste0(studio, " (n=", n_titles, ")"))
ggplot(studio_summ,
aes(y = reorder(studio_label, median_score), x = median_score)) +
geom_errorbarh(aes(xmin = q1, xmax = q3),
height = 0, linewidth = 0.7, color = art_mid) +
geom_point(aes(size = n_titles, color = tv_share), alpha = 0.95) +
geom_vline(xintercept = 6.38, linetype = "dashed",
linewidth = 0.7, color = art_highlight, alpha = 0.7) +
scale_color_viridis_c(option = "D",
labels = percent_format(accuracy = 1),
name = "TV share") +
theme_artometrics() +
labs(
title = "Bones and KyoAni lead — consistency across volume is the real achievement",
x = "Median MAL score", y = NULL,
caption = "Source: MyAnimeList via TidyTuesday (2019) | — ARTOMETRICS"
)
ggsave("chart2_studio_consistency.png", path = "charts",
width = 12, height = 7, dpi = 300, bg = "white")
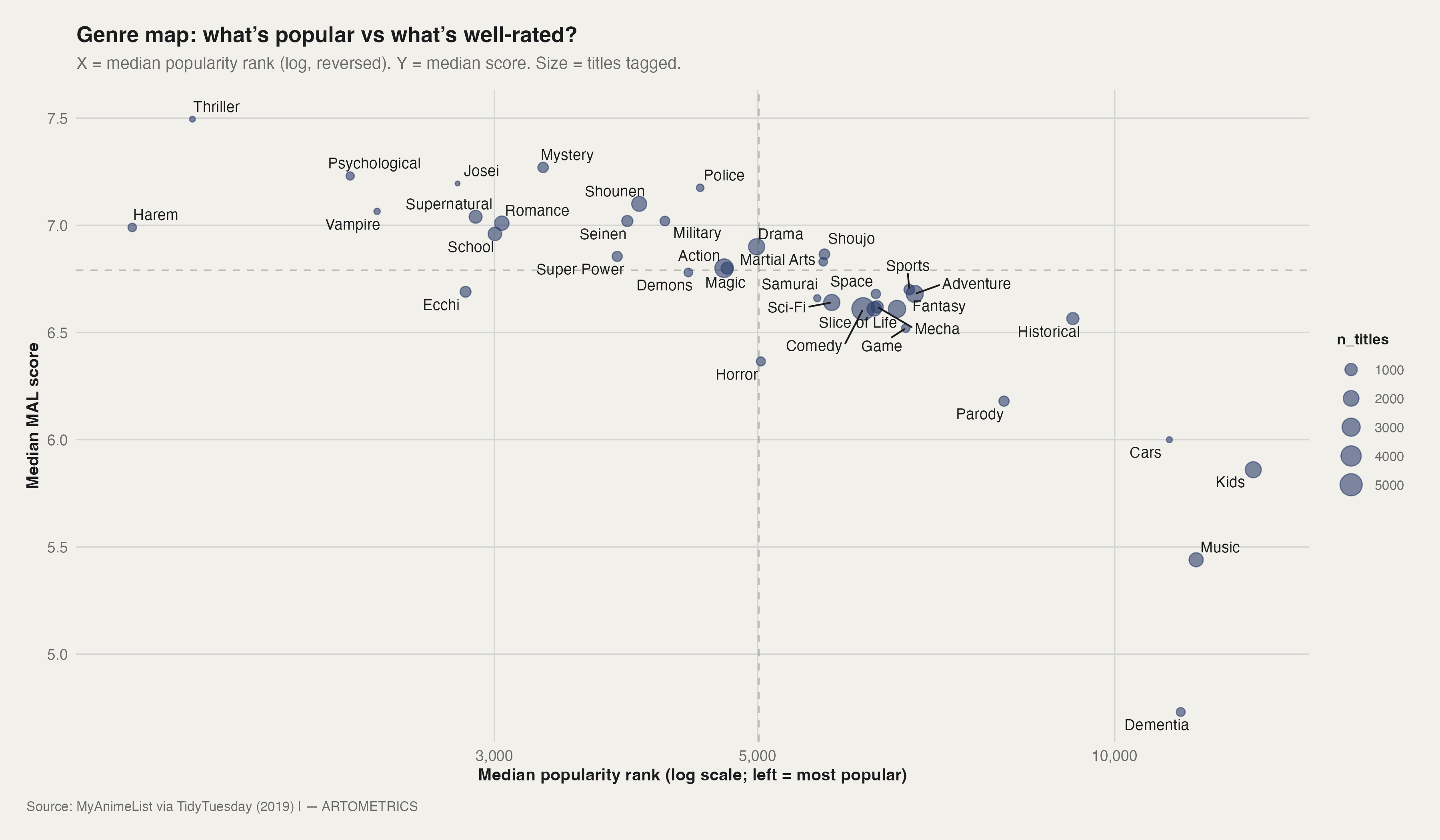
The genre map plots every major genre against two axes: how popular its titles are (X, log-reversed so most popular is right), and how well-rated they are (Y). Size encodes volume. The Main Hall — Action, Comedy, Fantasy, Adventure — sits in the dense center-right cluster. Massive reach, enormous volume, medians diluted to the mid-6s by sheer output. These are the genres that define what most people think anime is.
The Curator's Rooms are the upper-left quadrant. Thriller sits alone at the top: highest median on the chart (~7.5), extremely low popularity rank. The genre barely exists by volume, but almost everything made in it is exceptional. Mystery and Psychological follow the same pattern — high score, mid-obscurity — which aligns with their SQL performance. Historical sits far right: highly rated but ignored algorithmically. The starkest bottom outlier is Dementia: low popularity, low score, tiny volume.
Kids and Music are the bottom-right anchors — widest audiences, lowest scores. This is the self-selection problem in reverse: the MAL platform's adult userbase applying adult critical frameworks to children's media and promotional content. The scores are not wrong given who is rating them. They are simply the wrong instrument for the material. The genre map's quadrant structure is the clearest single visualization of what the platform is: a tool built by and for a specific audience, measuring everything — including content that was never made for them — against that audience's preferences.
genre_stats <- anime_genres %>%
distinct(animeID, genre) %>%
filter(genre != "") %>%
inner_join(
anime %>% select(animeID, score, popularity) %>%
filter(score > 0, popularity > 0),
by = "animeID"
) %>%
group_by(genre) %>%
summarise(
n_titles = n_distinct(animeID),
score_med = median(score),
pop_med = median(popularity),
.groups = "drop"
) %>%
filter(n_titles >= 80)
ggplot(genre_stats,
aes(x = pop_med, y = score_med, size = n_titles)) +
geom_vline(xintercept = median(genre_stats$pop_med),
linetype = "dashed", color = art_mid, alpha = 0.4) +
geom_hline(yintercept = median(genre_stats$score_med),
linetype = "dashed", color = art_mid, alpha = 0.4) +
geom_point(color = art_secondary, alpha = 0.6) +
scale_x_reverse(trans = "log10", labels = comma) +
geom_text_repel(aes(label = genre), size = 3.2,
color = art_dark, max.overlaps = Inf,
show.legend = FALSE) +
theme_artometrics() +
labs(
title = "Genre map: what's popular vs what's well-rated?",
x = "Median popularity rank (log scale; left = most popular)",
y = "Median MAL score",
caption = "Source: MyAnimeList via TidyTuesday (2019) | — ARTOMETRICS"
)
ggsave("chart3_genre_map.png", path = "charts",
width = 12, height = 7, dpi = 300, bg = "white")
The dataset ends in April 2019. Demon Slayer, Jujutsu Kaisen, Chainsaw Man, Spy × Family are entirely absent. Their exclusion almost certainly understates ONA growth, understates action/Shounen dominance, and means any claims about current genre trends require updating against the post-2019 streaming landscape. The industry restructured significantly around Netflix and Crunchyroll originals after this cutoff — the format and source material charts would look different with five more years of data.
MyAnimeList is an enthusiast platform. Its userbase skews adult, male, and English-speaking relative to anime's actual global audience. Two direct consequences appear in the data: Kids and Music programming are systematically underscored because the rating population is not the target demographic, and shows with strong Western fandom overlap (Fullmetal Alchemist: Brotherhood, Death Note) may be overrepresented in the elite tiers. The platform measures what its users value, which is not the same as what anime's full global audience values.
Genre tags are not mutually exclusive, and studio medians for boutique operations (n < 30) are statistically fragile. White Fox's strong studio ranking rests on 33 titles — a single poor season could meaningfully shift it. Thriller's top-ranked genre position rests on a small title count. Both results are directionally interesting and statistically fragile, and should be read as signals worth investigating rather than settled conclusions.
Anime transformed its distribution model three times in a century: from a theatrical craft economy built for prewar audiences, to a home-video OVA market that bypassed broadcast entirely, to an industrialized TV machine running on seasonal 12-episode contracts, and finally into a diversified platform ecosystem where ONA and streaming have created a fourth distribution channel that did not exist before 2010. Each transition was driven by access — whoever controlled the path to viewers controlled the format that dominated production.
Through all of it, two structural facts held. TV is the primary engine for quality output — 8.12% hit-rate, the highest of any format, confirmed by both the SQL aggregation and the genre map's quadrant structure. And popularity and quality are correlated but not causal — the feedback loop runs both directions, the algorithm amplifies existing popularity rather than discovering hidden quality, and the score-members correlation of r = 0.389 confirms the relationship is real but far from deterministic.
Ninety high-scoring titles sit past popularity rank 2,000 — past the point any algorithm will surface them. The catalog is vast. The attention economy is ruthless. If you want the best statistical odds, shop the seasonal TV hits in Mystery, Shounen, or Romance. But if you are willing to walk past the algorithm's edge, there are 90 titles waiting with scores above 8.0 and audiences small enough that they never quite made the trending list.
MyAnimeList Dataset (2019). TidyTuesday, April 23, 2019. Retrieved from: github.com/rfordatascience/tidytuesday
MyAnimeList. (n.d.). About MyAnimeList. Retrieved from myanimelist.net/about.php
Clements, J., & McCarthy, H. (2015). The Anime Encyclopedia: A Century of Japanese Animation (3rd ed.). Stone Bridge Press.
Condry, I. (2013). The Soul of Anime: Collaborative Creativity and Japan's Media Success Story. Duke University Press.
Denison, R. (2015). Anime: A History. BFI/Palgrave Macmillan.
Steinberg, M. (2012). Anime's Media Mix: Franchising Toys and Characters in Japan. University of Minnesota Press.
This report was researched, written, designed, and produced in active collaboration with Claude AI (Anthropic). The data pipeline, statistical analysis, chart design, written analysis, narrative structure, and visual styling were all developed through a directed partnership between human editorial judgment and AI execution. The research questions and brand vision are ours. The execution is a collaboration.
— Artometrics Editorial