This report analyzes the TidyTuesday 2025-06-03 release on Project Gutenberg — 100,000 rows after cleaning and merge. Which subjects dominate the public-domain canon?
Five charts track record counts across time, category, and named entities — trend, leaders, distribution, tiers, and relationships. Where companion files exist in the repo, they are joined before analysis so reception, geography, or metadata columns are not left on the table.
FAST FACTS
DATASET CONTEXT
The source is the TidyTuesday release from 2025-06-03 (R for Data Science community). This working file contains 100,000 rows and 3 columns after merging all available CSV/XLSX tables in the week folder.
Charts are exported as Plotly JSON with PNG fallbacks. Medians are used for robustness where distributions skew. Index-style fields (row numbers, sequential IDs) are excluded from metric selection.
How to read this report: start with the chart caption, then ask what the metric actually means, what a non-expert should notice first, and what an expert would challenge in the source. The goal is not to memorize every number; it is to leave with a sharper question than the one you arrived with.
Reader path: if you are new to the topic, treat each chart as a guided tour of one question: who leads, how concentrated the field is, what changes over time, and where the outliers sit. If you already know the domain, use the same charts as a challenge: check whether the metric is the right proxy, whether the source omits an important population, and whether the headline survives the limitations section.
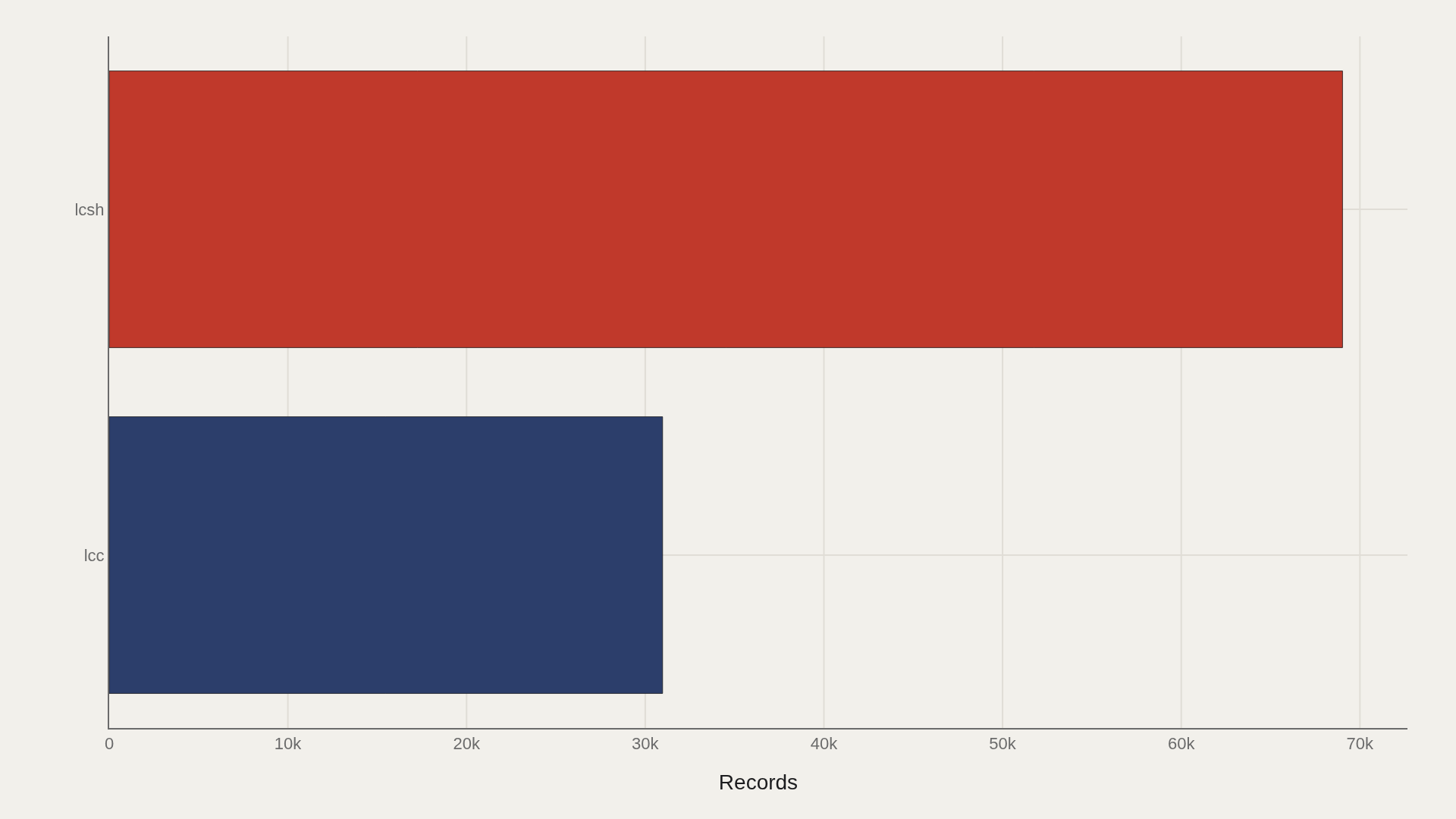
CHART 1 — LANDSCAPE
lcsh dominates with 69,027 records.
The main bucket carries the story; this field does not have a meaningful long-tail split.
CHART 2 — LEADERS
PS appears 4,684 times — the most recurring name in the file.
The top dozen account for a visible share of all 100,000 rows.
CHART 3 — CATEGORY
lcsh is the largest bucket with 69,027 records.
Category concentration shows where editorial attention should focus first.
SUPPLEMENT — FREQUENCY
Most subject entities appear only once; a small head revisits repeatedly.
This power-law shape is typical of guest lists, credits, and catalog-style tables.
SUPPLEMENT — NAMES
PS appears 4,684 times — the most repeated entry.
Frequency leaders reveal franchise depth when numeric scores are sparse.
LIMITATIONS
Community-cleaned TidyTuesday snapshots are not live APIs. Missing values, spelling variants, and week-of-export coverage limits apply. Merged tables may fan out or duplicate rows when join keys are imperfect.
Findings describe the file on hand — treat them as structural signals about Project Gutenberg, not exhaustive truth about the full domain.
CONCLUSION
Read as a teaching map, Project Gutenberg shows why one metric is rarely enough: leaders, tails, trends, and relationships each answer a different question about the field.
The best reading is modest: use the chart to sharpen the question, then check the source and limits before turning it into a claim.
REFERENCES
Data Science Learning Community. (2025). TidyTuesday: Project Gutenberg. https://raw.githubusercontent.com/rfordatascience/tidytuesday/main/data/2025/2025-06-03/gutenberg_subjects.csv
EDITOR'S NOTE
Artometrics data report from the TidyTuesday research pipeline. Charts and aggregates are reproducible from the embedded exhibits and public source files.